

1 引言
(1)轨迹—路网的全局匹配方法[10,11,12,13,14]以完成地理位置采样的轨迹数据为研究对象,通过数据后处理方法,提取轨迹中几何、语义、距离权重、个性偏好等特征,将轨迹数据匹配到道路网络。Yin等[10]将轨迹中采样点到道路弧段的距离作为道路弧段的权重,利用最短路径方法计算加权道路图中的最短路径,将其作为轨迹-道路匹配结果,高需等[11]则以用户历史轨迹中的个性偏好作为权重因子进行路网匹配。Nikolić等[12]对轨迹数据滤波并通过聚类和位置投影的方式建立轨迹采样点与道路节点和道路弧段的关联关系,构建轨迹—路网候选匹配集,然后根据基因遗传算法(Generic Algorithm, GA)选取最佳路网匹配结果。Lou等[13]与李清泉等[14]根据轨迹中几何和拓扑等特征构建最短路径候选匹配集,然后通过轨迹采样点之间的时间、空间、速度等约束条件,构建轨迹—路网匹配关系。这类方法以事后推定的方式计算轨迹—路网匹配关系,需要顾及整个轨迹数据特征,能够处理长时间间隔的路网匹配问题,但方法计算速度较慢,一般用于离线地图匹配。
(2)轨迹—路网的局部/增量匹配方法[9,15-19]基于轨迹数据的时空采样过程,建立轨迹—路网局部匹配关系。Brakatsoulas等[17]基于自由空间(Free Space)理论计算轨迹曲线与道路网络之间的Fréchet距离,根据轨迹和路网的局部相似的几何特征性进行增量式轨迹—路网匹配。针对轨迹采样点之间的时空连续特征,Newson等[18]和Song等[19]根据隐马尔可夫模型(Hidden Markov Models, HMM)计算轨迹中的采样点与道路网络之间的概率匹配关系,以采样点到相邻道路弧段的距离和道路中不同采样位置之间的最短路径计算HMM的发射概率和转移概率,得到轨迹与道路网络的匹配结果。Liu等[9]针对基于HMM的路网匹配方法中存在的标记偏置问题,提出时空条件随机场(Spatial and Temporal Conditional Random Field, ST-CRF)方法,训练路网匹配特征函数权重参数,通过HMM中类似的解码方法计算轨迹-路网匹配结果。这类方法利用轨迹的局部特征进行路网匹配,计算速度较快,通过已匹配路网局部/增量延伸,最终得到全局最优匹配结果,可用于在线地图匹配,但匹配结果容易受到轨迹噪声的影响,或依赖“贪心算法”策略寻找最优解。
车辆在地理空间运动产生的时空位置记录,是一个动态的地理位置采样过程的结果,而粒子滤波(Particle Filter, PF)作为一种序贯蒙特卡罗(Sequential Monte Carlo)方法,具有一定的时空模型模拟能力[20,21],能够根据上一时刻观测值、当前时刻模型模拟值与观测值,通过粒子重采样和权重更新优化当前模型模拟结果,可处理轨迹中的噪声并减少轨迹—路网匹配过程中对已匹配结果准确性的依赖,因此可利用PF方法对行车轨迹中车辆的时空运动过程进行模拟,建立行车轨迹—路网的匹配关系。基于此,本文利用PF原理对行车轨迹中车辆的时空运动过程进行建模,在拓扑关联的道路弧段中生成粒子,构建行车轨迹与道路网络的匹配方法,并通过行车轨迹为研究对象,对方法的可靠性和准确性进行实验和分析。
2 粒子滤波与轨迹—路网匹配
2.1 粒子生成
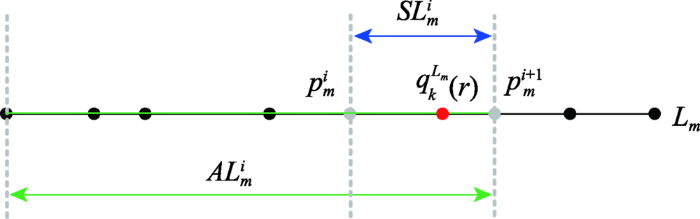
本文以行车轨迹采样点邻近的道路节点拓扑关联的道路弧段为粒子生成区间,所有粒子均位于相邻道路弧段,是一个沿道路线性度量空间分布的二维空间采样点,其中行车轨迹中采样点和相邻道路弧段的关系表示如下:
(1)假定沿着行车轨迹S中车辆运动方向,与轨迹采样点Si(xi, yi)相邻近j个道路节点N{N1, N2, …, Nj};
(2)与道路节点Nk∈N相邻的l个道路弧段L{L1, L2, …, Ll}中,存在一条道路弧段Lm∈L,其中每条道路弧段Lm由n个顶点p{p1, p2, …, pn}组成;
在PF过程中,需要在粒子采样空间生成o个随机粒子q{q1, q2, …, qo}。为使得生成粒子具有随机性,粒子的生成需要满足2个条件:① 粒子q在l个道路弧段L中产生的概率具有随机性;② 粒子q在道路弧段Lm∈L的几何坐标具有随机性。
因此,可通过随机数生成索引m∈[1, 2, …, l]从L中选取道路弧段Lm。然后,根据随机长度比例r∈[0,1]从Lm中生成粒子
图1
(1)依次计算道路弧段Lm中相邻顶点
(2)计算由弧段起点至弧段顶点
(3)根据随机长度比例r,计算粒子坐标
(4)最终得到沿道路网络弧段线性度量空间随机分布的初始化随机粒子
2.2 行车轨迹—路网匹配
在传统的PF方法中,粒子随机分布在研究区域中,并随着行车轨迹采样点的状态变化不断更新,从而更新采样点的位置坐标。而在本文行车轨迹—路网匹配方法的计算过程如下:
(1)从车辆运动产生的行车轨迹采样点出发,搜索邻近的道路节点,根据道路节点拓扑邻接的道路弧段初始化产生随机粒子;
(2)通过行车轨迹中车辆运动模型更新粒子在道路弧段中的位置,利用粒子与下一时刻轨迹采样点的地理位置计算粒子权重,并统计每条拓扑邻接道路弧段的粒子权重,进行粒子重采样,根据行车轨迹采样时刻迭代更新轨迹采样位置与粒子状态;
(3)当搜索到新的邻近道路节点时,计算各条道路弧段的累计粒子权重,计算累计粒子权重最大的道路弧段作为匹配道路弧段;
(4)以道路节点为匹配关系分界线,更新行车轨迹与路网的匹配关系,返回步骤(1)并根据新的道路节点及拓扑邻接道路弧段集合自动生成随机粒子采样,不断迭代直至车辆完全停止运动。行车轨迹—路网匹配算法的流程如图2所示。
图2
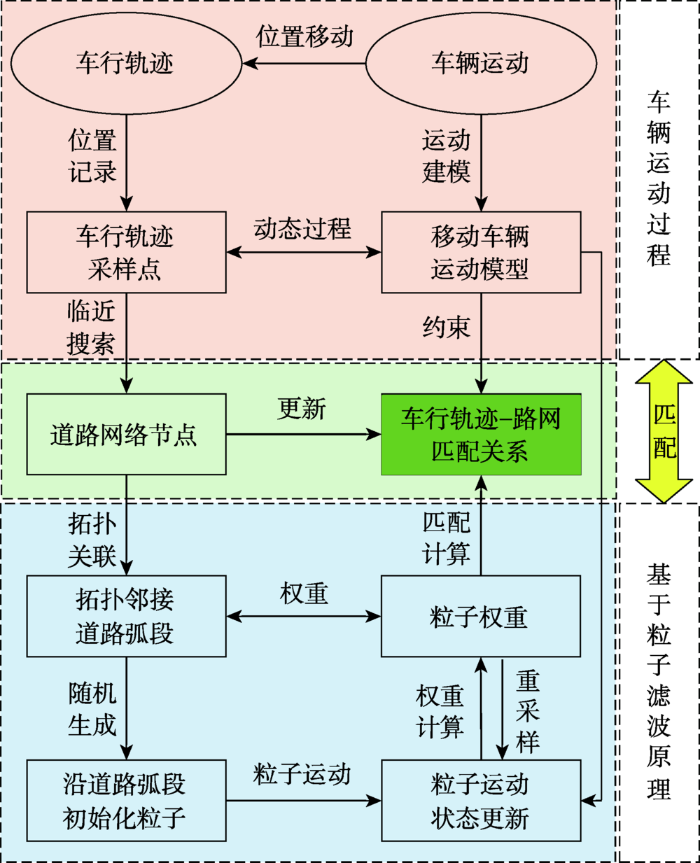
图2
基于粒子滤波的车行轨迹—路网匹配算法流程
Fig. 2
The workflow of vehicle trajectory- map matching algorithm
基于PF原理的行车轨迹—路网匹配方法,假定输入行车轨迹S,轨迹中车辆匀速运动速度为v,运动模型过程的噪声标准差为
式中:
(1)搜索与行车轨迹中采样点Si距离小于d的道路网节点
①如果是首次初始化粒子,则准备开始PF过程模拟;
②否则,统计每条邻接道路弧段
(2)根据轨迹中车辆运动方向,根据采样时间先后顺序从行车轨迹中顺序选取采样点Si;
(3)根据PF原理和轨迹中车辆运动模型,在邻接道路弧段
(4)计算粒子与行车轨迹采样点的距离D,根据式(6)计算粒子权重w
(5)归一化权重,并对粒子重采样;
(6)重复步骤(1)、(2)(3),直至采样点Si以距离d搜索到新的道路节点,则返回步骤(1)。
其中,粒子重采样方法为随机重采样,通过不断迭代选择权重较大的粒子作为新的粒子,然后利用车辆运动模型计算下一时刻粒子状态。PF粒子权重的影响因素主要为轨迹采样点在不同时刻的位置以及粒子权重函数式(6)。在该过程中可能会存在粒子退化现象,但是由于本文方法中行车轨迹采样点在每条道路弧段中移动时间较短,并且在道路节点处重新生成粒子,因此,粒子退化现象对本文方法的影响较为有限。
3 行车轨迹—路网匹配实验结果与 分析
3.1 实验数据
本文采用行车轨迹为实验对象,由两条长时间序列采集的行车轨迹组成。其中,行车轨迹的长度约为102 km,轨迹采样点共计1838个;水平采样精度为10 m,采样时间间隔为10 s。具体情况如表1所示。
表1 车行轨迹采样信息
Tab. 1
| 轨迹 | 采样点数 | 总长度/m | 采样时长/s |
|---|---|---|---|
| 车行轨迹1 | 1251 | 77 090 | 12 500 |
| 车行轨迹2 | 587 | 25 397 | 5860 |
研究区域中道路数据和辅助遥感影像来自于该区域的基础地理数据库,研究区域面积约为55 km2,道路中路网分布比较复杂,在部分区域路网密度较高。数据空间分布如图3所示。
图3
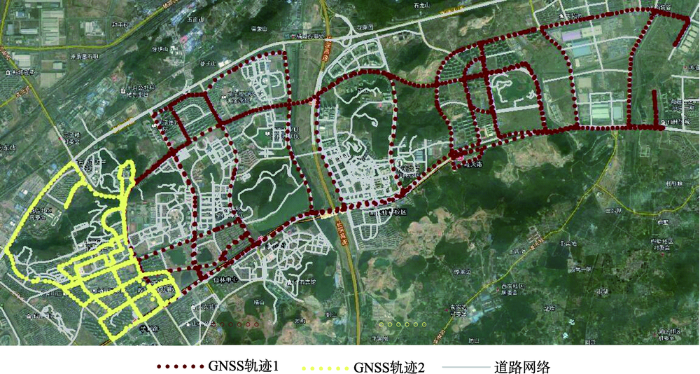
图3
研究区域中车行轨迹与道路网络空间分布
Fig. 3
The spatial distribution of vehicle trajectories and road networks in the research region
3.2 实验结果与分析
3.2.1 数据预处理与参数选择
行车轨迹—路网匹配过程中,首先需要对数据进行拓扑检查,根据道路数据构建具有弧段和节点结构的道路网络,同时对行车轨迹进行离群值粗差剔除等预处理,然后根据PF原理实现行车轨迹与路网的匹配。其中,相关参数的选取方法如下:
(1)计算每个道路节点及其最邻近道路节点之间的距离,以所有道路节点最邻近道路节点距离平均值的2倍,作为轨迹采样点搜索邻近道路节点的范围d的参考值,在本文实验中d的值为70 m;
(2)假定在相邻轨迹采样点之间车辆的运动速度v为匀速,由于本文道路数据中未提供道路限速信息,因此车辆运动速度可通过当前时刻和之前时刻轨迹采样点的距离及其时间间隔计算得到,将行车轨迹中相邻轨迹采样点之间距离平均值的0.5倍作为运动模型的过程噪声标准差
(3)以道路网络中道路弧段长度的平均值作为高斯概率密度函数标准差σ的参考值,在本文实验中σ的值为1000 m;
(4)根据道路网络中每个道路节点的复杂程度作为随机粒子个数o的参考依据,在道路节点复杂程度较高的道路数据中设置较大的粒子数目,反之亦然。在本文实验中与道路节点邻接的道路弧段数目以4条为主,因此可设置随机粒子个数o为100。
3.2.2 粒子的随机生成
在行车轨迹中采样点滤波初始时刻,粒子在道路弧段中是随机生成的,如图4所示,假定一条道路弧段由9个顶点组成(绿色小圆点),从弧段起点到弧段终点,根据式(1)和式(2)计算各个顶点组成的子弧段在道路弧段中的累计长度比例,分别为0%、21%、31%、43%、55%、67%、76%、87%、100%(绿色字体),初始时刻在道路弧段中随机生成5个粒子,在道路弧段中的长度比例分别为17%、38%、52%、80%、94%(红色字体),则根据长度比例以式(3)在相应的子弧段中计算粒子在道路弧段中的几何位置(红色大圆点)。由图可见,粒子能够利用随机生成的长度比例,根据粒子坐标计算公式,分别分布在道路弧段的不同子弧段中。
图4
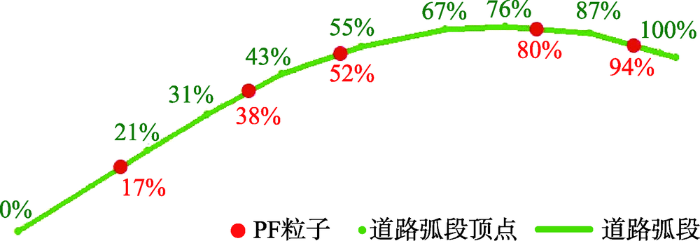
图4
基于道路弧段的粒子生成
注:绿色数字为各个顶点组成的道路子弧段累计长度比例,红色数字为随机粒子组成的道路子弧段累计长度比例。
Fig. 4
Particles generation based on road arc
3.2.3 粒子移动与路网匹配
根据邻近道路节点拓扑关联的道路弧段生成粒子,然后利用PF原理对行车轨迹采样点和粒子每个时刻的状态进行更新,最后根据累计粒子权重匹配道路弧段,过程如图5所示。
图5
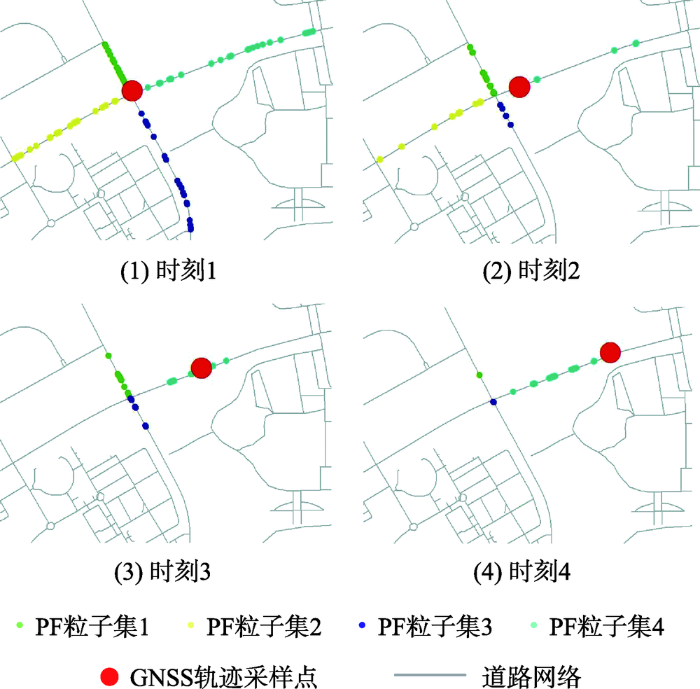
图5
轨迹采样点不同时刻粒子位置的变化
Fig. 5
The position changes of particles at different time of sampling points
由图5可见,在初始时刻1,轨迹采样点(红色大圆点)搜索到道路节点有4条邻接道路弧段,分别在每条道路弧段中生成粒子集(其他颜色小圆点),在时刻2,车辆位置更新后轨迹采样点移动到下一时刻,道路弧段中粒子的数量和位置得到更新,在时刻3,随着轨迹采样点位置的更新,粒子的空间分布发生较大变化,开始集中在待匹配道路弧段,在时刻4,粒子则集中在了待匹配道路弧段,这条弧段中的粒子数量显著增多,进而可以通过每条道路弧段的累计粒子权重判断出行车轨迹—路网的匹配结果。由图可见,本文方法能够根据PF原理,更新不同行车轨迹位置采样时刻的粒子在道路弧段中的位置,并通过这个过程,计算待匹配道路弧段的累计粒子权重,实现行车轨迹与道路网络的匹配。
3.2.4 行车轨迹—路网匹配
为了对本文方法路网匹配能力进行实验对比,首先,基于距离判别法将轨迹点与邻近道路网络弧段进行距离投影,根据轨迹点与邻近道路弧段的距离计算其匹配关系,对行车轨迹1和行车轨迹2进行实验,结果如图6所示。
图6
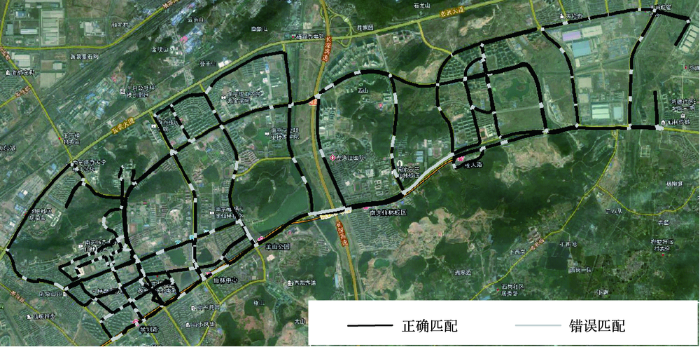
图6
基于距离判别法的车行轨迹—路网匹配结果
Fig. 6
The vehicle trajectory-map matching result based on the distance method
在图6基于距离判别方法的实验结果中,黑色实线为与行车轨迹正确匹配的道路弧段,灰色实线为与行车轨迹错误匹配的道路弧段。由图可见,行车轨迹1和行车轨迹2均匹配到了邻近道路弧段,但匹配结果在道路节点处存在较多错误匹配,导致行车轨迹-路网匹配结果在时间和空间上存在一定的不连续性,与轨迹中车辆运动情况存在不一致。
利用本文基于PF的行车轨迹-路网匹配方法对研究区域中行车轨迹和道路网络进行匹配,实验结果如图7。图中黑色实线为与行车轨迹正确匹配的道路弧段,灰色实线为与行车轨迹错误匹配的道路弧段,灰色虚线为与行车轨迹未匹配的道路弧段。由图可见,行车轨迹-路网匹配结果覆盖了大部分区域,而在局部路网密度较高的复杂通行区域存在一定的错误匹配结果,本文方法能够从行车轨迹中计算出轨迹-路网匹配关系。
图7
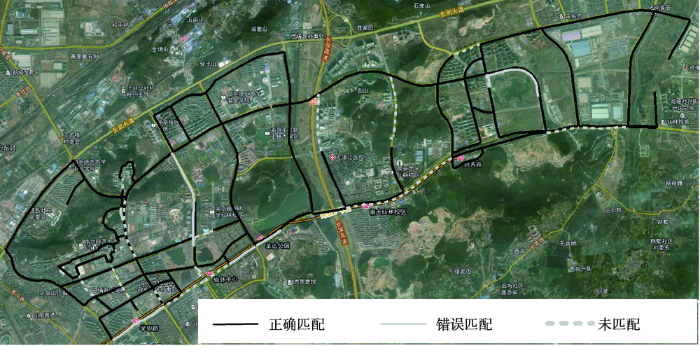
图7
本文基于PF方法的车行轨迹-路网匹配结果
Fig. 7
The vehicle trajectory-map matching result based on PF
本文以用“正确匹配长度/轨迹总长度”计算行车轨迹-路网匹配结果的正确率。对实验结果进行统计,分别从匹配长度、正确匹配、错误匹配、未匹配进行统计,结果如表2所示。
表2 车行轨迹-路网匹配结果统计
Tab. 2
| 实验方法 | 轨迹 | 匹配长度 | 正确匹配 | 错误匹配 | 未匹配 |
|---|---|---|---|---|---|
| 距离判别法 | 车行轨迹1 | 77 746 | 64 994 | 12 752 | 0 |
| 车行轨迹2 | 26 424 | 21 252 | 5172 | 0 | |
| 本文方法 | 车行轨迹1 | 71 220 | 65 921 | 5299 | 8882 |
| 车行轨迹2 | 25 057 | 23 621 | 1436 | 2578 |
在基于距离判别法的实验结果中,行车轨迹 1的正确匹配路网长度为64 944 m,路网的匹配准确率为84.24%,而行车轨迹2的正确匹配路网长度为21 252 m,路网的匹配正确率为83.68%,行车轨迹1和行车轨迹2的路网匹配长度均比实际行车轨迹长度大,因此,路网匹配结果中均存在明显的过匹配现象;在本文方法实验结果中,行车轨迹1匹配路网长度为71 220 m,其中正确匹配路网 65 921 m,未匹配路网长度8882 m,路网匹配正确率为85.51%,行车轨迹2匹配路网长度为25 057 m, 其中正确匹配路网23 621 m,未匹配路网长度2578 m,路网匹配的正确率为93.01%。由表可见,本文方法能够在较为复杂的道路网络中建立行车轨迹-路网的正确匹配关系,对85%以上的行车轨迹建立匹配关系,同时能够使匹配结果具有时空连续性。
通过实验结果可见,本文方法基于PF原理构建行车轨迹-路网匹配方法,使得路网匹配方法在计算过程中不依赖于全局或局部/增量式匹配过程的寻优条件,使得计算过程具有相对独立性,具有较高的匹配准确率并且行车轨迹-路网匹配结果具有路径连续性,与车辆实际运动情况较为一致。
4 结论
行车轨迹—路网匹配方法往往需要顾及行车轨迹中采样点的时空连续特征。现有行车轨迹—路网匹配方法利用采样点的全局或局部时空连续特征,依赖“贪心算法”寻优策略或易受轨迹噪声影响,获得的路网匹配结果准确性和时空连续性存在一定的不足。本文基于PF原理通过3个方面构建行车轨迹—路网匹配关系:① 利用行车轨迹的采样点邻近道路网络弧段随机生成粒子;② 通过轨迹中车辆运动模型计算不同轨迹采样时刻下粒子的运动状态,根据粒子与轨迹采样点之间的距离误差计算粒子权重,进行粒子重采样并更新粒子状态; ③ 根据每条道路弧段中的累计粒子权重对行车轨迹与道路网络进行匹配。实验表明,本文方法对长度约为102 km的较长时间采样序列的行车轨迹进行路网匹配,路网匹配结果的正确率大于85%,能够基于PF原理将行车轨迹与道路网络进行准确地匹配,使得匹配过程具有相对独立性,同时保持匹配结果的时空连续性。本文方法具有一定的实时运算能力,可对较大研究区域中行车轨迹数据通过并行运算方式对本文方法的在线行车轨迹-路网匹配进一步研究。
参考文献
出租车轨迹数据挖掘进展
[J].
Recent progress in taxi trajectory data mining
[J].
路网匹配算法综述
[J].
Survey of map matching algorithms
[J].
Computing with spatial trajectories
[M].
Current map-matching algorithms for transport applications: State-of-the art and future research directions
[J].
轨迹大数据:数据处理关键技术研究综述
[J].
Trajectory big data: A review of key technologies in data processing
[J].
一种改进的快速浮动车地图匹配方法
[J].
An improved algorithm for fast map-matching of floating car
[J].
面向复杂城市道路网络的GPS轨迹匹配算法
[J].
Map-matching algorithm for GPS trajectories in complex urban road networks
[J].
路网更新的轨迹—地图匹配方法
[J].
Renewal of road networks using map-matching technique of trajectories
[J].
A ST-CRF map-matching method for low-frequency floating car data
[J].
A weight-based map matching method in moving objects databases
[C]//
基于偏好的个性化路网匹配算法
[J].
Personalized map-matching algorithm based on drive preference
[J].
Implementation of generic algorithm in map-matching model
[J].
Map-matching for low-sampling-rate GPS trajectories
[C]//
一种基于约束的最短路径低频浮动车数据地图匹配算法
[J].
Flowing car data map-matching based on constrained shortest path algorithm
[J].
一种路网拓扑约束下的增量型地图匹配算法
[J].
An incremental map-matching method based on road network topology
[J].
Adaptive fastest path computation on a road network: A traffic mining approach
[C]//
On map-matching vehicle tracking data
[C]//
Hidden Markov map matching through noise and sparseness
[C]//
Hidden Markov model and driver path preference for floating car trajectory map matching
[J].
Application of particle filters to a map-matching algorithm
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}